
Have you ever wanted to extract data from a website but found yourself blocked by login screens and authentication processes? Well, fear not! In this article, we’ll explore the fascinating world of web scraping C# with login, where we’ll learn how to bypass these obstacles and collect the data we need.
Web scraping, the process of extracting information from websites, is becoming increasingly important in today’s data-driven world, and C# is a powerful programming language that can help you automate this process. So, let’s dive in and discover how to scrape data from password-protected sites using C# and login authentication.
Understanding Web Scraping
Web scraping is the process of extracting data from websites, and it has become an essential tool for businesses and individuals alike. With the vast amount of information available on the internet, web scraping allows you to gather valuable insights and automate tasks that would otherwise be time-consuming and error-prone.
There are various techniques that can be used for web scraping, from simple copy-pasting of data to complex web crawlers and bots. However, regardless of the technique used, web scraping can be classified into two main categories: static and dynamic.
Static web scraping involves extracting data from websites that have static content, meaning that the content remains the same every time the page is loaded. This type of scraping is relatively simple and can be done using basic tools such as HTML parsers and regular expressions.

Dynamic web scraping, on the other hand, involves extracting data from websites that have dynamic content, meaning that the content changes every time the page is loaded. Dynamic web scraping requires more advanced techniques, such as browser automation and JavaScript rendering, to interact with the website and extract the data.
When scraping data from websites, it’s important to consider the legal and ethical implications. Some websites have terms of service agreements that prohibit web scraping, and scraping too much data too quickly can cause server overload and impact website performance. Therefore, it’s essential to be mindful of the websites you are scraping and to ensure that you are doing it in a responsible and ethical manner.
Overall, web scraping is a valuable tool for extracting data from websites, and with the right techniques and considerations in place, it can be a powerful tool for businesses and individuals alike.
Getting Started with C#
If you’re interested in web scraping, C# is a powerful programming language that can help you automate the process. C# is an object-oriented language that is easy to learn and provides a wide range of features and libraries for web scraping.
To get started with web scraping with C#, you first need to set up your development environment. You will need to install Visual Studio or another C# IDE and download the necessary libraries and packages, such as HtmlAgilityPack and Selenium WebDriver.
Once you have your development environment set up, you can start writing code to scrape data from websites. C# provides a range of features for web scraping, including HTML parsing, regular expressions, and browser automation.

One of the most common methods of web scraping with C# is using the HtmlAgilityPack library. This library allows you to parse HTML documents and extract data using XPath expressions. Alternatively, you can use Selenium WebDriver to automate browser interactions and scrape data from dynamic websites.
Overall, C# is a versatile language that can be used for web scraping, and with the right libraries and tools, you can easily automate the process of extracting data from websites. So, if you’re interested in web scraping, C# is a great language to get started with.
Scraping Data with Login
Scraping data from websites that require login authentication can be challenging, but it’s essential when dealing with password-protected content. Fortunately, C# provides powerful tools and libraries that can help you scrape data with login authentication.
Before scraping data with login, you need to understand how login authentication works. Login authentication is a process where a user is authenticated by the website using their username and password. The website then sets a session or a cookie to keep track of the user’s authenticated state.
To scrape data with login authentication, you need to capture and store the login credentials, which can be done using various methods such as reading from a file, prompting the user for input, or even storing the credentials in a secure database. Once you have the login credentials, you can use them to authenticate with the website using sessions or cookies.

One of the most popular libraries for scraping data with login authentication in C# is the Selenium WebDriver. Selenium WebDriver is a browser automation library that allows you to automate browser interactions and simulate user behavior. With Selenium WebDriver, you can automate the login process, extract data, and even interact with dynamic content.
Another library that can be used for scraping data with login authentication in C# is the HttpClient. The HttpClient library allows you to send HTTP requests and receive responses from a website. With HttpClient, you can authenticate with a website, extract data, and even download files.
Overall, scraping data with login authentication can be a challenging task, but with the right tools and libraries in C#, you can easily automate the process of extracting data from password-protected websites. So, if you need to scrape data from websites that require login authentication, C# is a great language to get started with.
Handling Data and Output
Once you have scraped the data from the website, the next step is to handle the data and output it in a useful format. C# provides various tools and libraries that can help you handle data and output it in different formats.
One of the most common ways to handle data in C# is to use collections such as arrays, lists, and dictionaries. These collections allow you to store and manipulate data in an organized way. For example, you can use arrays to store a collection of data that is of the same type, such as a list of integers or strings.
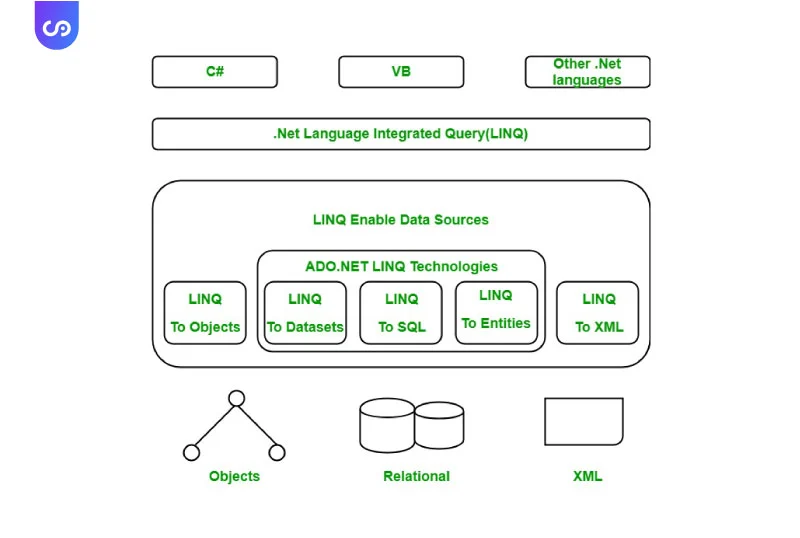
Another tool for handling data in C# is LINQ (Language-Integrated Query), which allows you to query data from collections, databases, and other data sources. With LINQ, you can easily filter, sort, and group data based on specific criteria.
Once you have handled the data, the next step is to output it in a useful format. C# provides various libraries for outputting data, including the CSVHelper library, which allows you to write data to CSV (Comma Separated Values) files. You can also use the JSON.NET library to serialize data to JSON (JavaScript Object Notation) format, which is commonly used for data exchange between applications.
In addition to CSV and JSON, C# provides libraries for outputting data in other formats such as XML (eXtensible Markup Language), HTML (Hypertext Markup Language), and even PDF (Portable Document Format) files.
Overall, handling data and outputting it in a useful format is an important step in web scraping with C#. With the right tools and libraries, you can easily manipulate data and output it in various formats to meet your needs. So, if you’re looking to get started with web scraping with C#, make sure to consider how you will handle and output the data you scrape.
Legal and Ethical Considerations
Web scraping can be a powerful tool for collecting data and information from websites. However, it’s important to consider the legal and ethical implications of web scraping to ensure that you’re operating within the bounds of the law and adhering to ethical principles.
First and foremost, it’s important to note that web scraping can be illegal in certain circumstances. For example, scraping data from websites that have explicitly stated that scraping is not allowed can result in legal action. Similarly, scraping data that is protected by copyright or other intellectual property laws can also be illegal.

Additionally, it’s important to consider ethical considerations when web scraping. While web scraping can be a valuable tool for collecting data, it’s important to ensure that you’re not infringing on the privacy of individuals or organizations. For example, scraping personal information such as email addresses or phone numbers without consent can be a violation of privacy rights.
To ensure that you’re operating within the bounds of the law and adhering to ethical principles when web scraping, it’s important to research the legal and ethical implications of web scraping in your specific context. This may involve consulting with legal experts or industry professionals who have experience in web scraping.
Overall, it’s important to approach web scraping with a responsible and ethical mindset. By considering the legal and ethical implications of web scraping, you can ensure that you’re collecting data in a responsible and ethical manner that respects the rights of individuals and organizations.
Conclusion
Web scraping with C# and login is a powerful technique that can enable you to extract valuable data and information from websites. While web scraping can be a complex and challenging process, C# provides a range of tools and libraries that can make it easier to scrape data and handle it in a useful format. However, it’s important to approach web scraping with a responsible and ethical mindset, taking into account legal and ethical considerations. By doing so, you can ensure that you’re collecting data in a responsible and ethical manner that respects the rights of individuals and organizations. So, if you’re looking to get started with web scraping with C# and login, make sure to take the time to understand the tools and techniques involved and approach it with a responsible mindset.
FAQs
What is web scraping with login in C#?
Web scraping with login in C# refers to the process of programmatically accessing a website that requires authentication or login credentials, and then extracting data from that website. This involves using C# code to handle authentication and login pages in order to access the desired data.
What are the common challenges in web scraping with login in C#?
Some common challenges in web scraping with login in C# include handling authentication tokens, managing cookies, dealing with dynamic content, and ensuring that the login process is successful. Additionally, some websites may employ anti-scraping techniques that make it more difficult to access the desired data.
How can I pass login credentials for web scraping with C#?
You can pass login credentials for web scraping with C# by making a POST request to the website’s login page, passing in the appropriate login credentials as form data. This can be done using the HttpClient class in C#.
What are the best C# libraries for web scraping with authentication?
There are several C# libraries that can be used for web scraping with authentication, including HtmlAgilityPack, AngleSharp, and ScrapySharp. These libraries provide functionality for handling authentication and login pages, as well as parsing HTML and extracting data.





